Dla wielu programowanie to tylko praca, dla mnie to sposób na uporządkowanie chaosu świata. Pod tagiem ‘Programowanie’ znajdziesz techniczne jądro moich działań. Jako Hud Hatman, patrzę na rzeczywistość przez pryzmat algorytmów – jeśli coś nie działa w systemie społecznym czy instytucjonalnym, traktuję to jak błąd w kodzie, który trzeba wyłapać i naprawić.
Tutaj nie znajdziesz teoretycznych rozważań. To konkret: fragmenty skryptów, architektura rozwiązań i logiczne struktury, które buduję, by udowadniać moje teorie matematyczne lub dokumentować naruszenia, z jakimi się mierzę. Programowanie to moja broń w walce o transparentność. Jeśli interesuje Cię, jak użyć kodu do debugowania rzeczywistości, jak pisać funkcje, które niosą za sobą matematyczną prawdę i jak zachować czystość logiczną w świecie pełnym ‘bugów’ – te wpisy są dla Ciebie. Wejdź głębiej w mój proces twórczy i zobacz, jak powstaje cyfrowy dorobek Michała Baniowskiego.
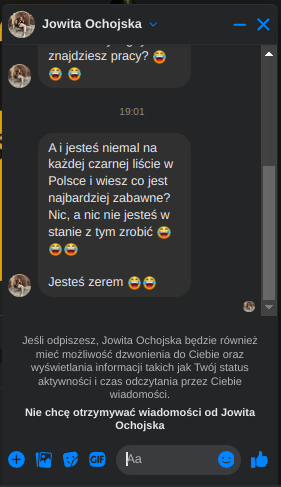
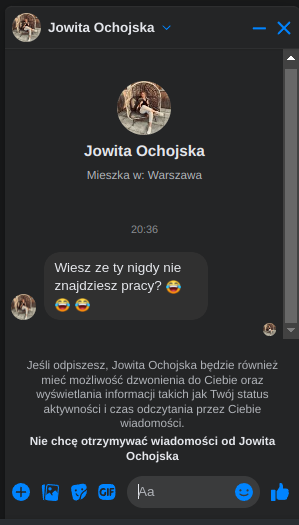
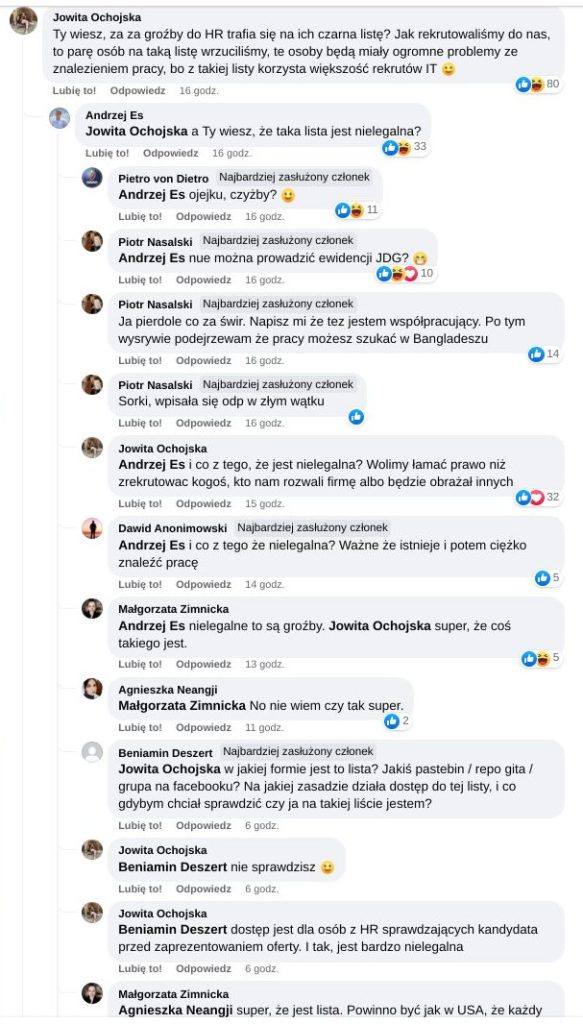
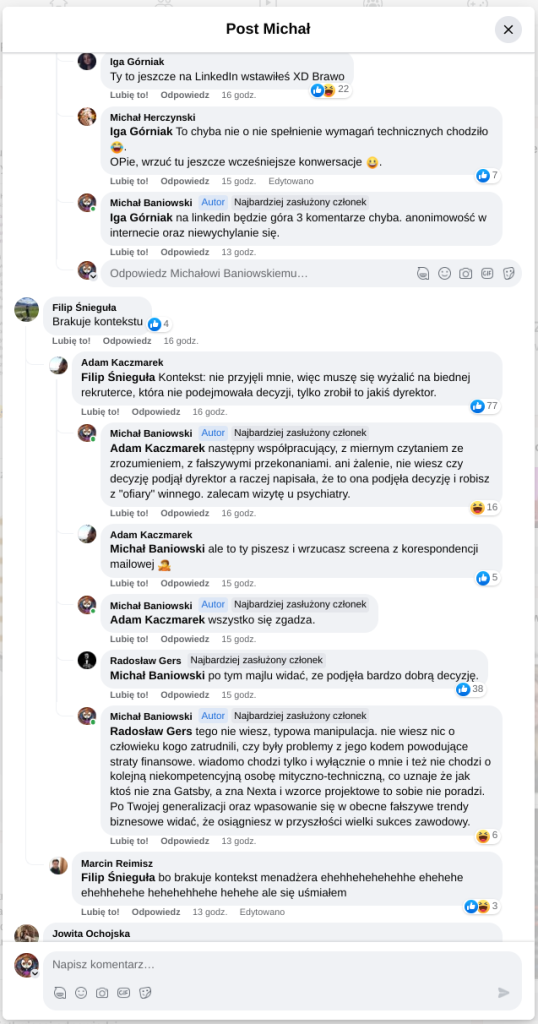
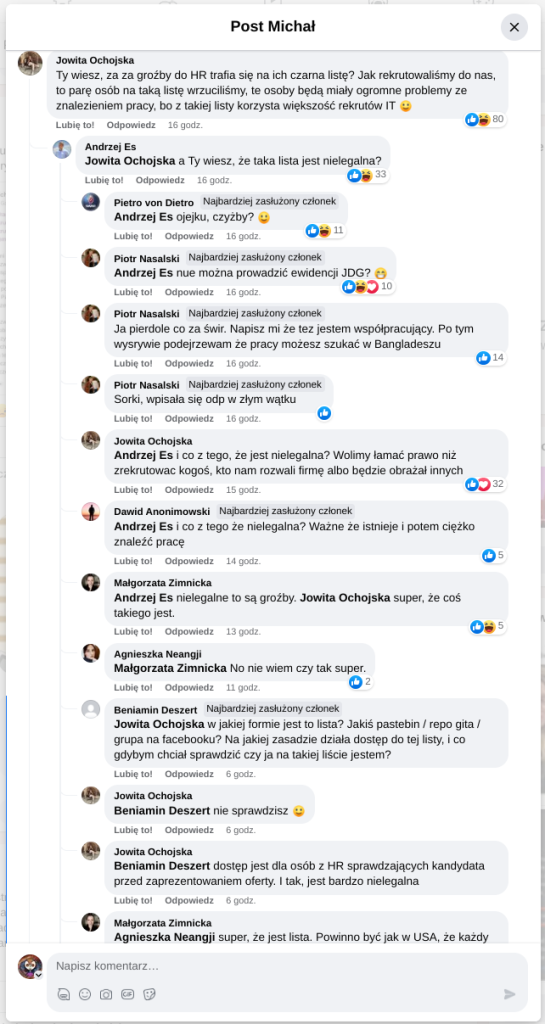
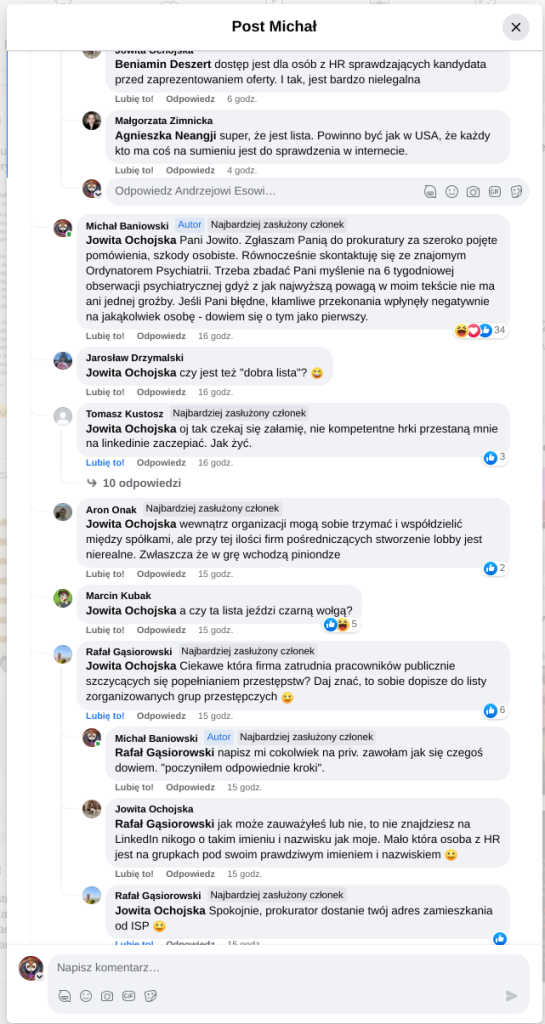
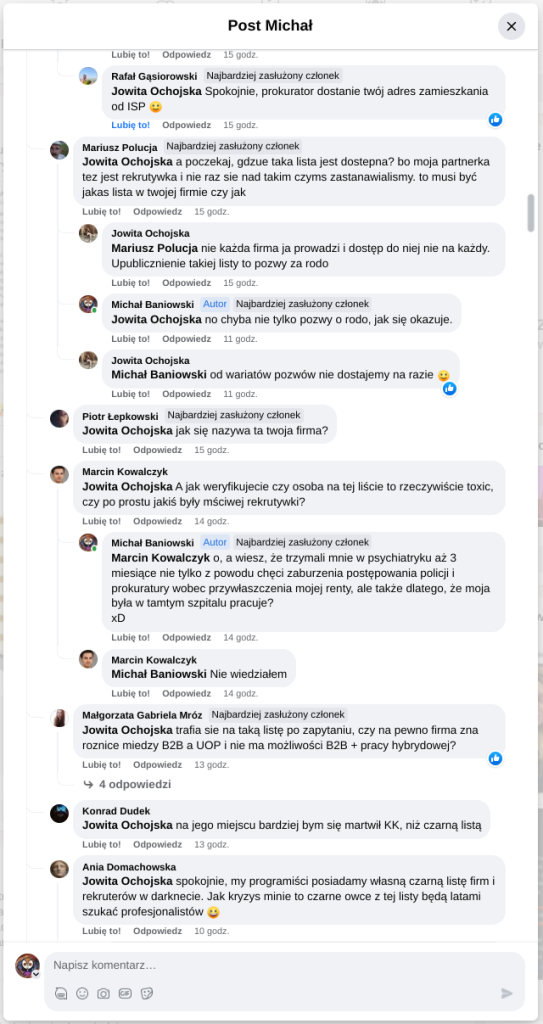
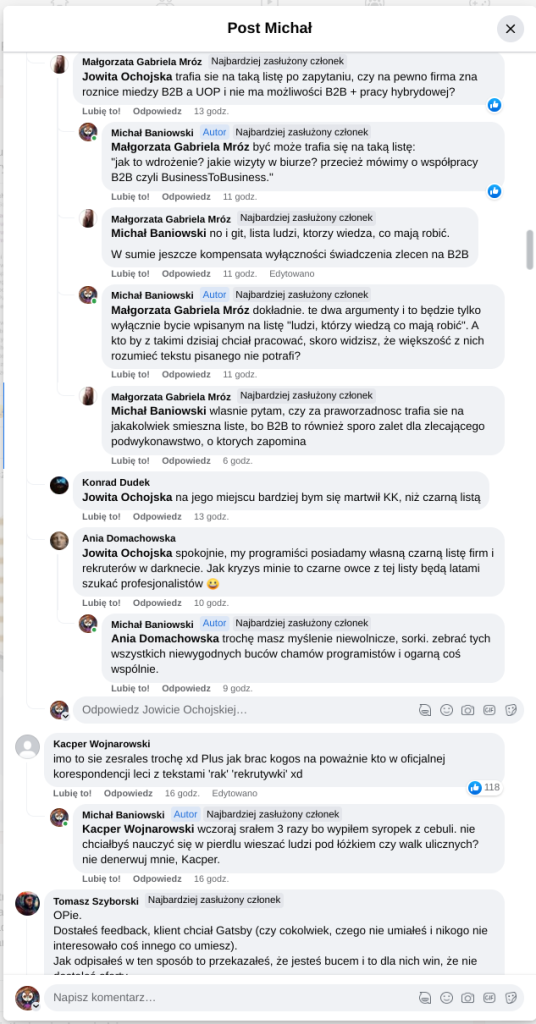
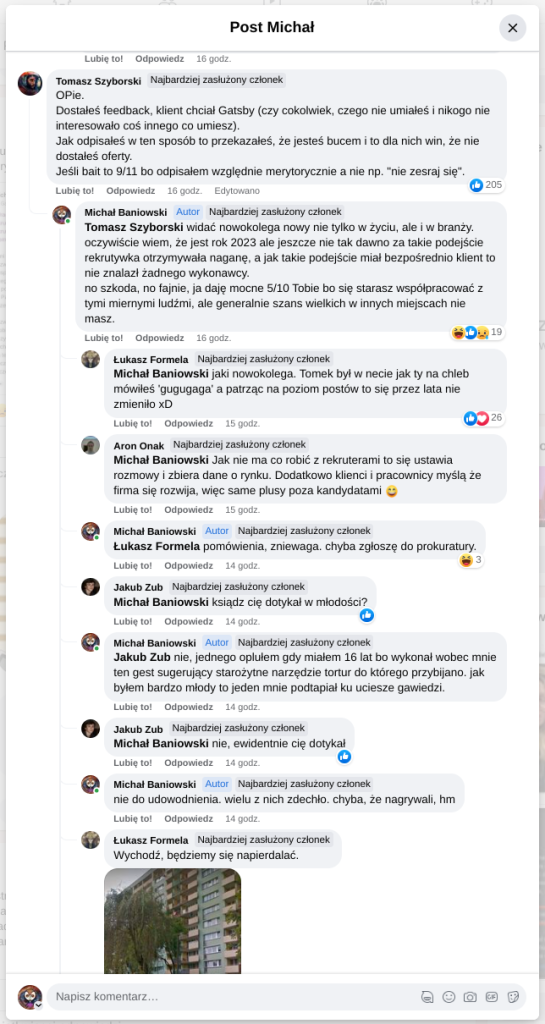
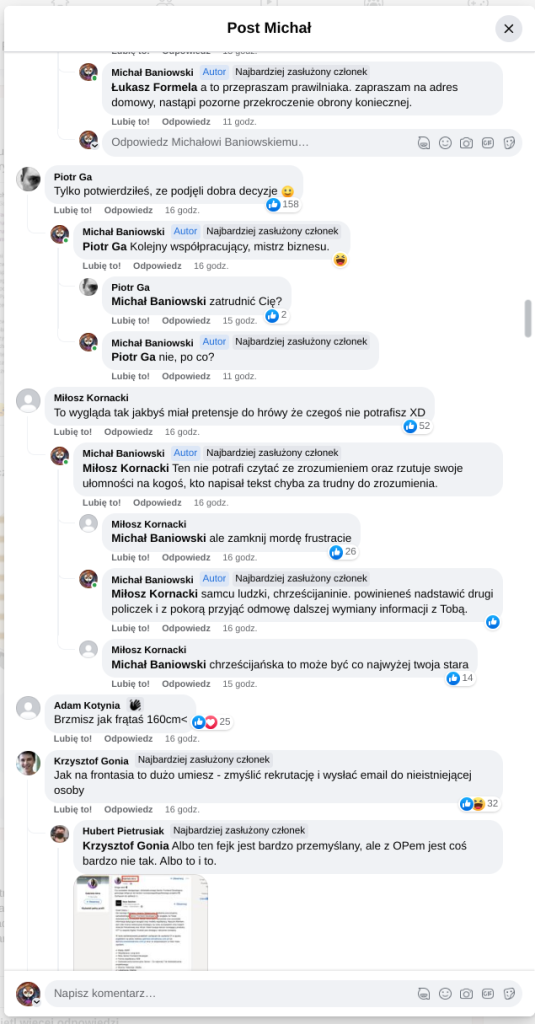
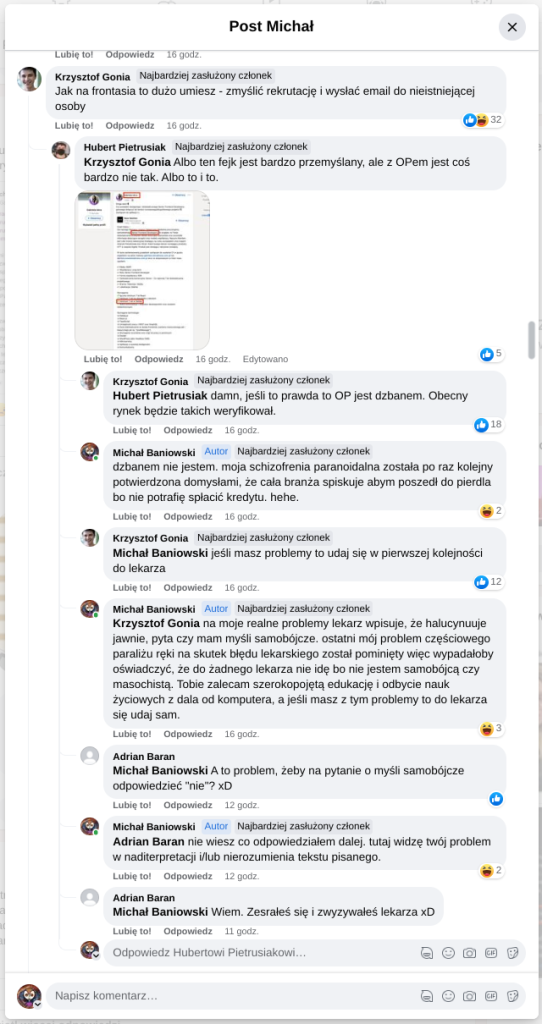
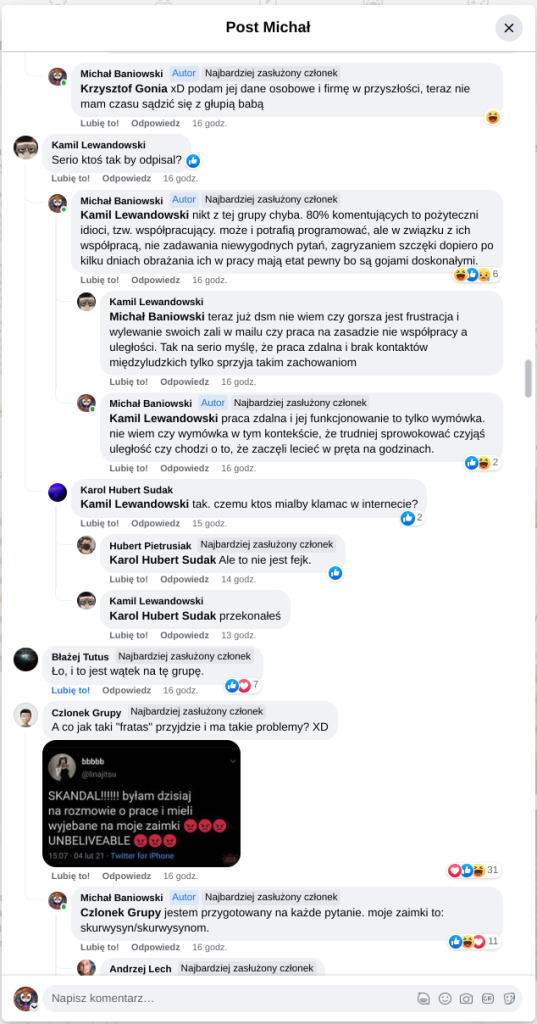
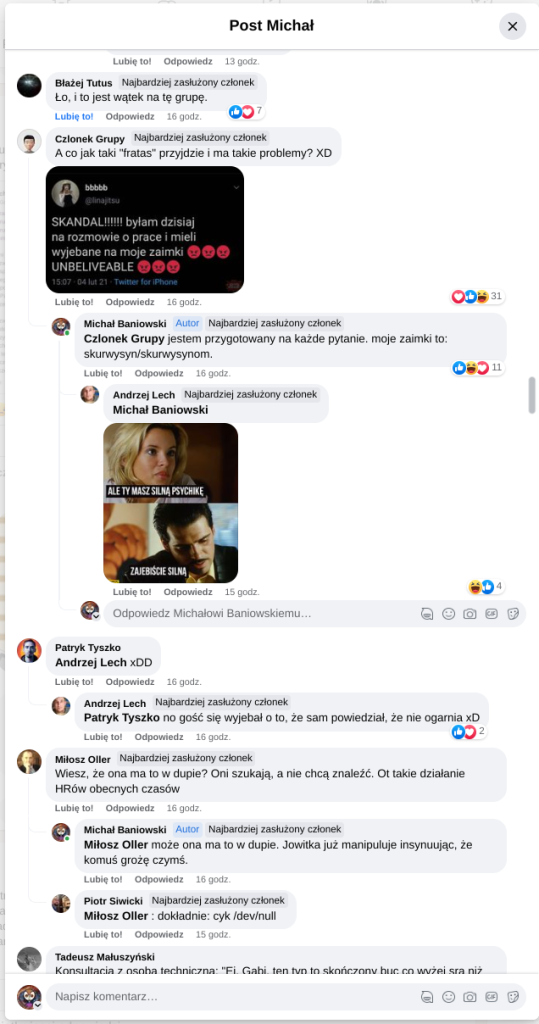
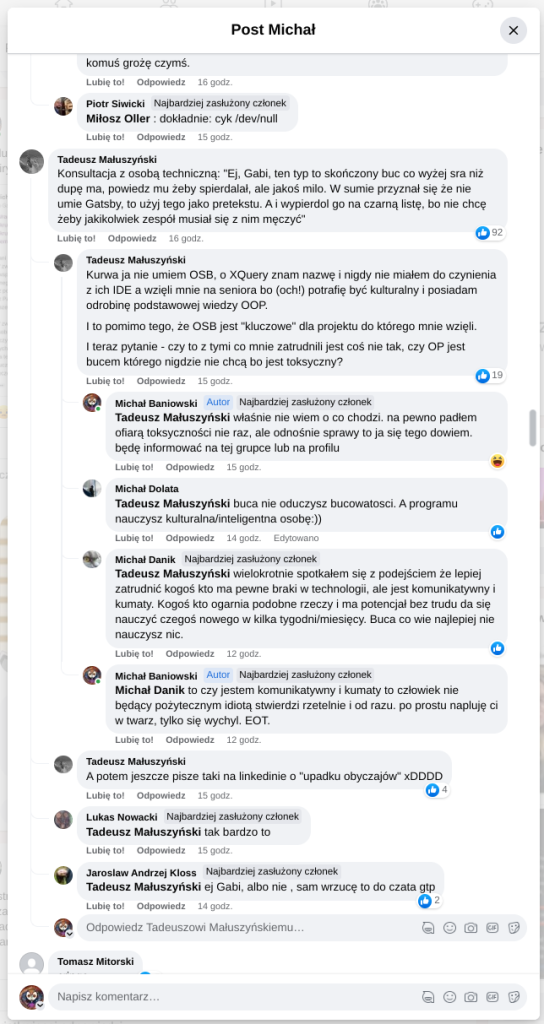
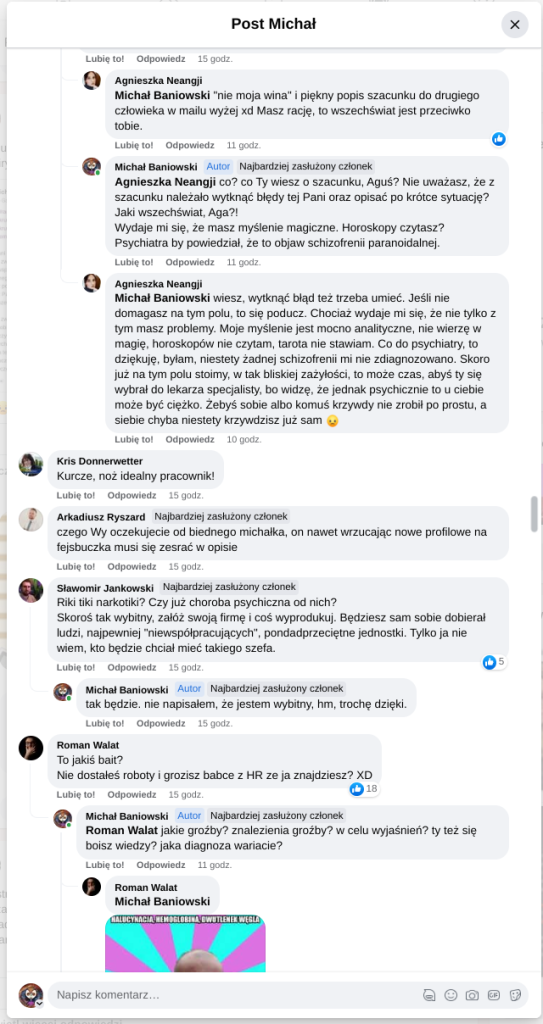
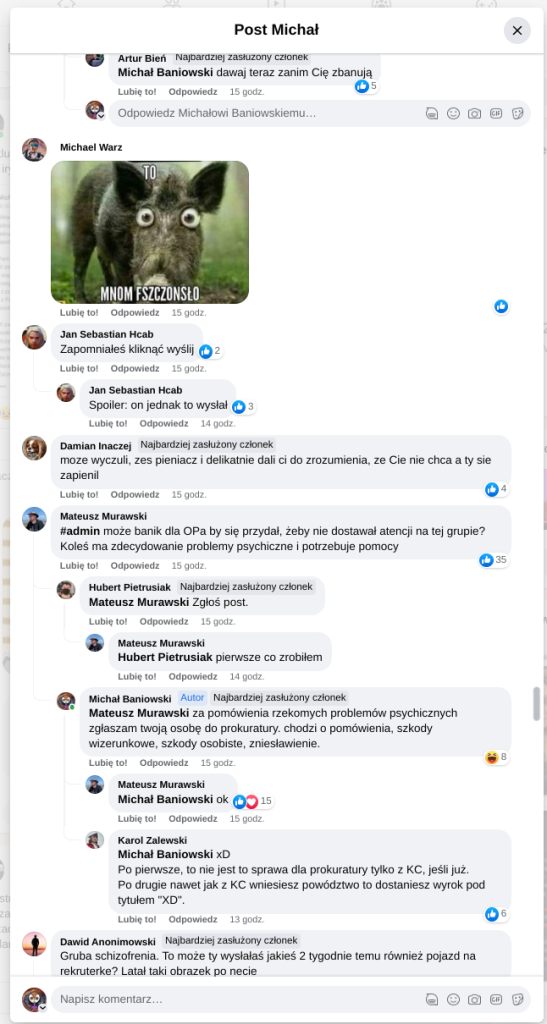
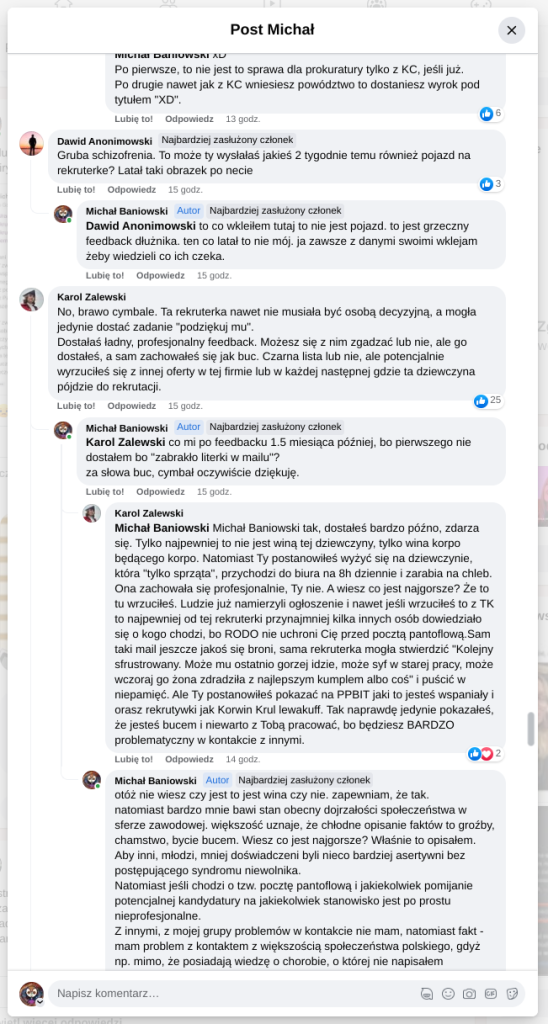
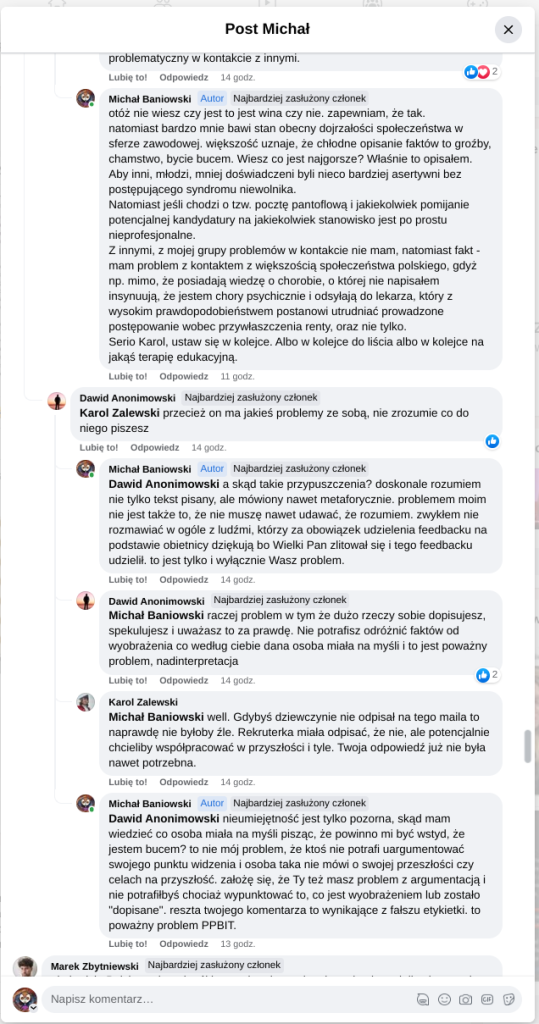
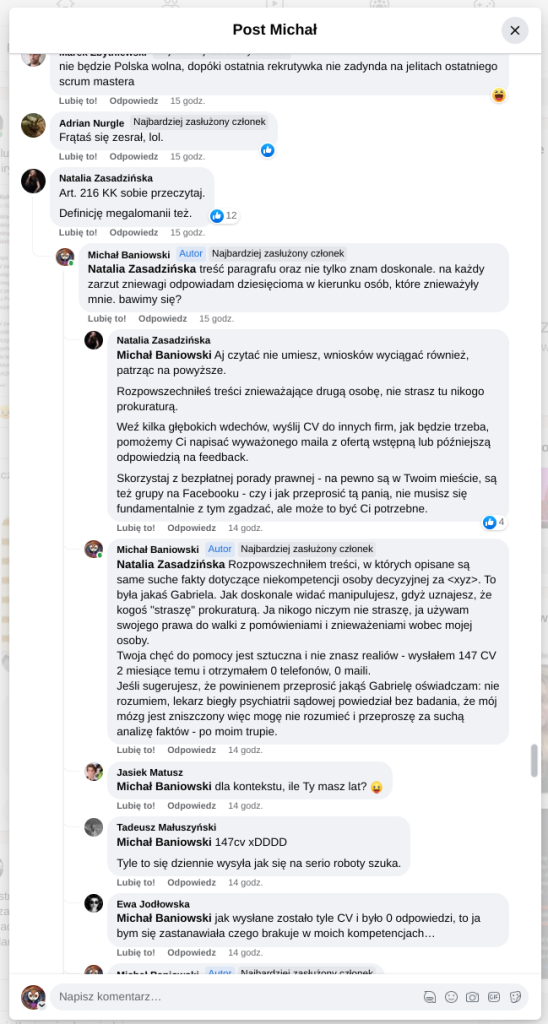
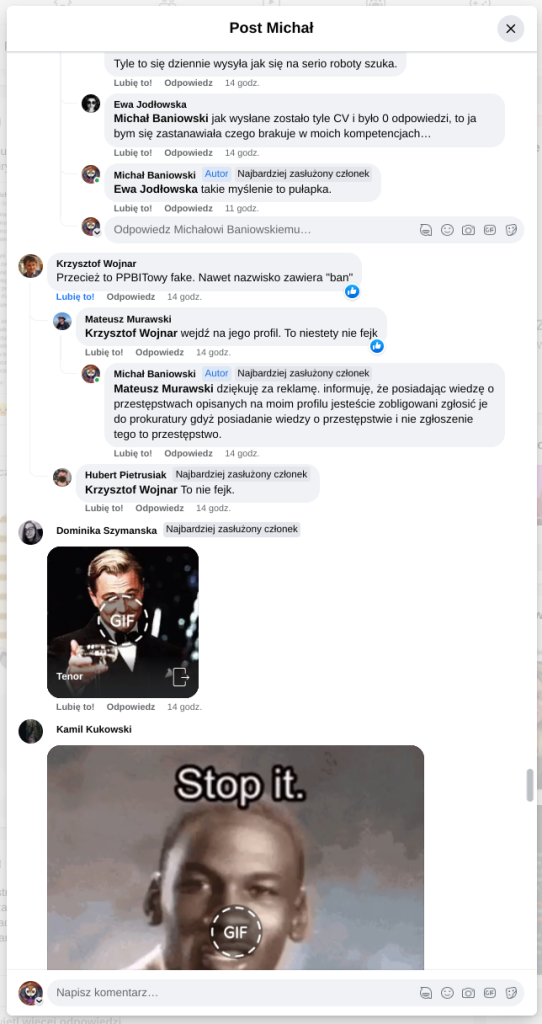
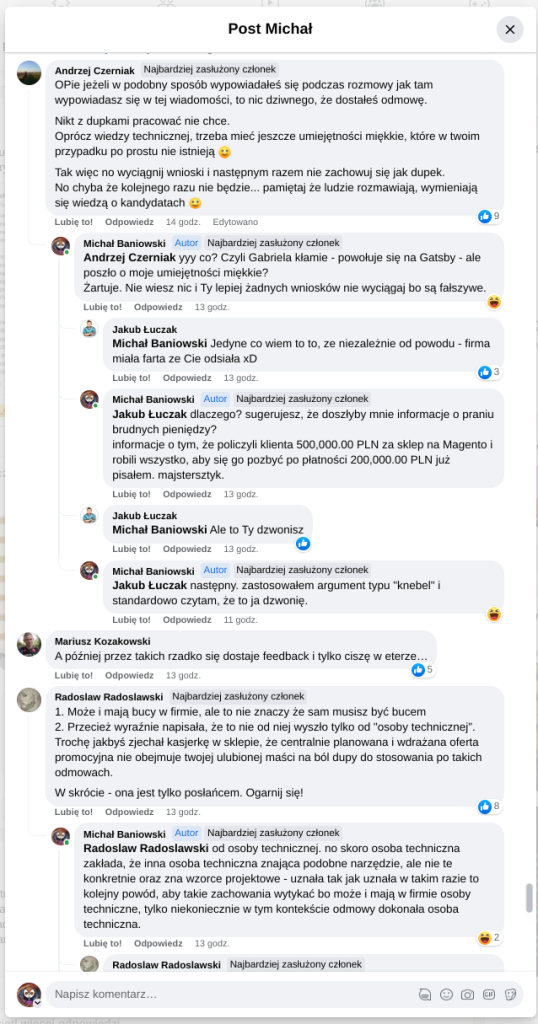
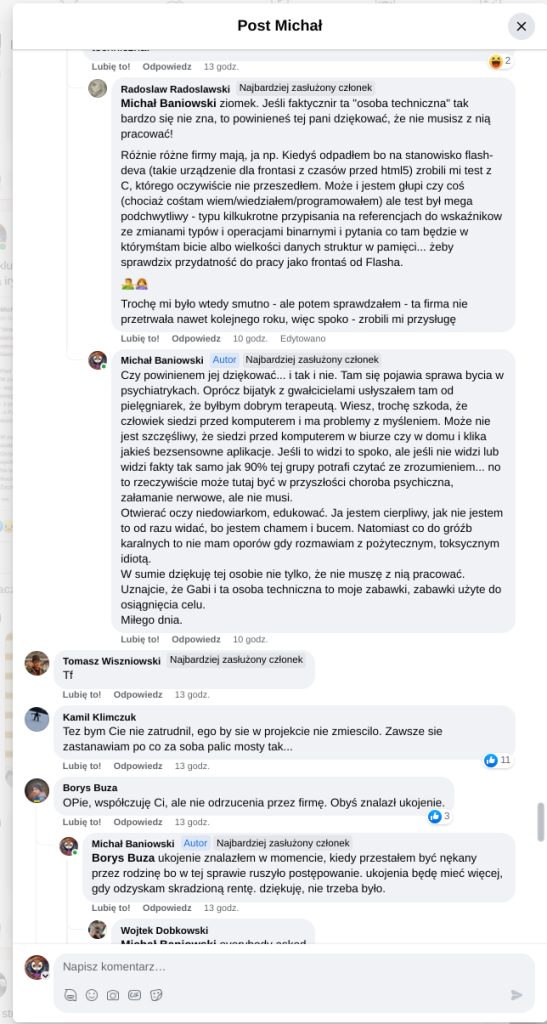
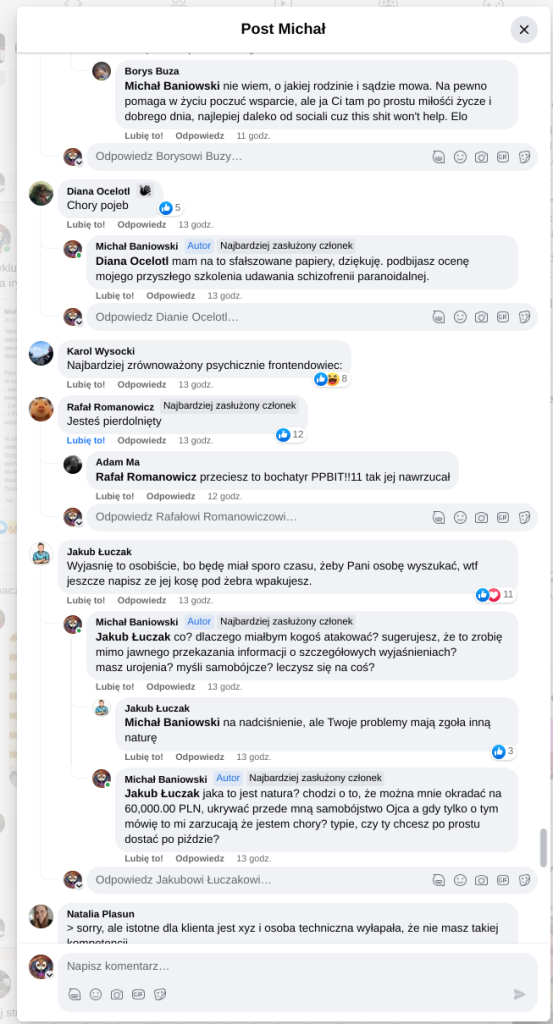
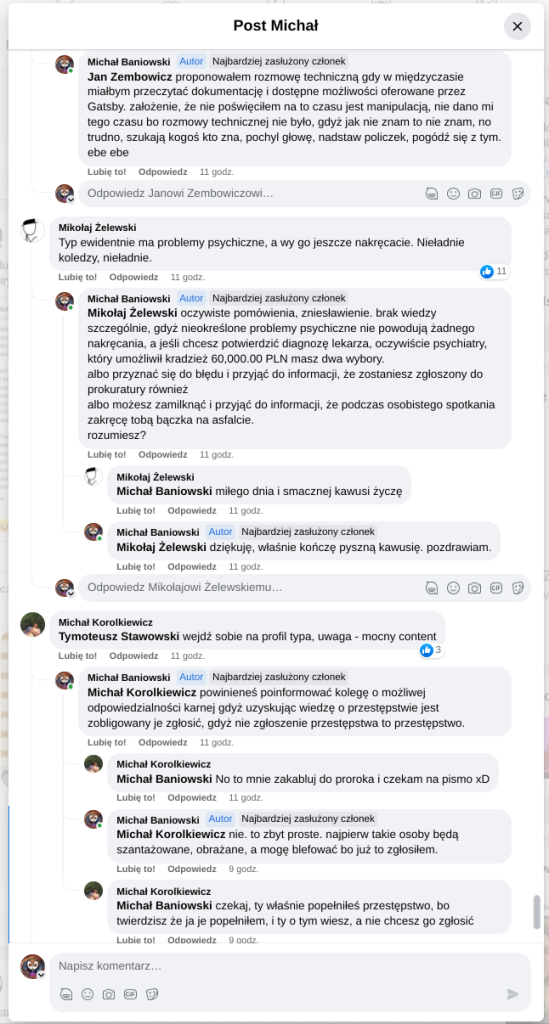
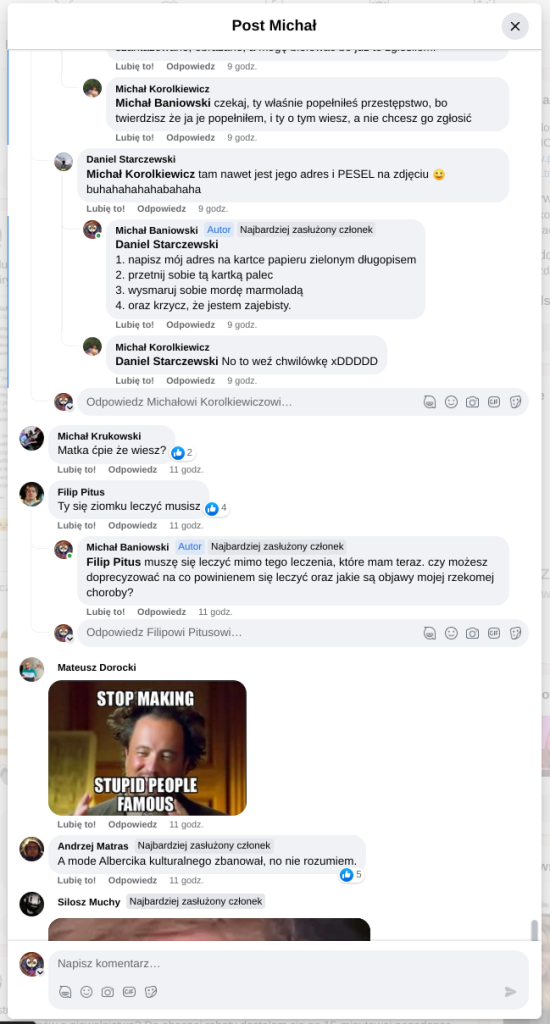
Pracujesz w IT, masz świetne skille, ale nagle telefony od rekruterów milkną? W tym wpisie poruszam temat, o którym w korporacyjnych kuchniach mówi się tylko szeptem: czarne listy HR. Jako programista i matematyk, Michał Baniowski (Hud Hatman), analizuję przerażające zjawisko dyskryminacji zawodowej, która uderza w osoby z historią w systemie psychiatrii.
Opisuję, jak wrażliwe dane medyczne, które powinny być pilnie strzeżone, wyciekają do działów kadr i stają się wyrokiem na Twoją karierę. To brutalny mechanizm selekcji, w którym „Imperium Kłamstwa” i korporacyjny cynizm idą pod rękę, by wyeliminować jednostki myślące niezależnie lub te, które system próbował złamać. Jeśli kiedykolwiek czułeś, że Twoja ścieżka zawodowa jest sabotowana przez niewidzialną rękę, ten tekst pokaże Ci, jak działają te mechanizmy i dlaczego walka o transparentność w branży IT jest kluczowa dla nas wszystkich.
Na tej podstronie znajduje się materiał dowodowy dyskryminacji podczas rekrutacji co prowadziło by do dyskryminacji na rynku pracy.
Nie posiadam informacji, czy taka osoba nazwana jowita ochojska istnieje, ale podejście było i jest często spotykane. Skoro chory to niech się leczy. Ja pierdole.
Reakcja społeczności była jasna. Wobec słów, że osoba z diagnozą schizofrenii paranoidalnej może pracować mówię: być może może pracować. Poza tym skąd w ogóle określają człowieka jako tego, który “halucynuuje jawnie”.
Shadowbanning w HR w polskiej branży IT
Skoro by taka osoba mogła pracować – bo rzekomo mógłbym – problemem nie jest diagnoza, a moja osoba – więc jest to problem osobisty i wycelowany w moją osobę. A dziękuję bardzo, wypierdalać.
Czy dwa teksty mogą być do siebie podobne, nawet jeśli nie używają tych samych słów? W świecie programowania nie zgadujemy – my to liczymy. W tym wpisie rozbieram na części pierwsze algorytm Cosine Similarity. Jako Hud Hatman, pokazuję Ci, jak zamienić nudne ciągi znaków w wektory i zmierzyć kąt między nimi.
To nie jest tylko sucha teoria. To narzędzie, które pozwala wyłapać, czy ktoś ‘przepisał’ dokumentację, czy dwa zeznania są podejrzanie identyczne, lub jak maszyny rozumieją sens naszych słów. Jeśli chcesz wejść poziom wyżej w analizie danych i dowiedzieć się, dlaczego cosinus jest Twoim najlepszym przyjacielem w NLP – ten tekst jest Twoim manualem. Matematyka nie kłamie, ona po prostu pokazuje strukturę prawdy.
Zadanie testowe sprzed 8. lat do firmy z UK, rzekomego bankruta Gluru.
Kod źródłowy w javascript z pogranicza machine learning. Nie znane wtedy rozwiązanie problemu, którego rozwiązanie polega na podobieństwie liczbowym w mapie słowa do innego słowa lub wielu słów – obsługuje zdefiniowane synonimy.
Odrzucone z powodu “zbyt skomplikowane”. Nowatorski powód odrzucenia przyznam.
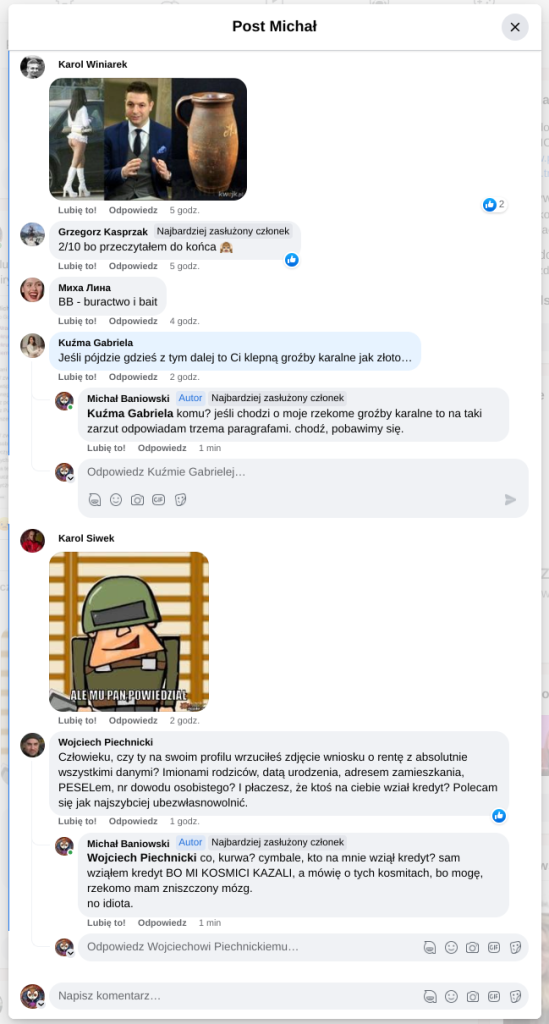
https://en.wikipedia.org/wiki/Cosine_similarity – na dzień 20.12.2025 0:52 brak wzmianki o pierwszym autorze Michale Baniowskim z Tychów. Internowany od 2018 roku 4 krotnie na oddziałach psychiatrii w polsce. Osadzony w areszcie z domniemaniem planowania ataków terrorystycznych. Trwa sprawa ubezwłasnowolnienia całkowitego tej osoby.
Będą dymy. Udostępniłem ten link wcześniej bez wyjaśnień. No czegoś tutaj nie mówią, zapewne by dali tabletki na schizofremie bo pacjent ma cyberpsychozę. Dobre dobre. Nie ma dowodów, że używacie funkcjonalności z AI od inwalidy.
“Jesteś teraz specjalistą IT – opisz algorytm parzenia herbaty.”
“Jesteś teraz sebixem z dzielni – opisz parzenie herbaty dla ziomeczka”
Opis użycia do tego macierzy i wektorów z odpowiednimi działaniami algebraicznymi wydaje się zbędny na dzień 7.02.2026.
Porównywarka tekstów (string similarity) Baniowskiego
Główna innowacja to obsługa synonimów z różnymi stopniami podobieństwa (wagi od 0 do 1).
Zamiast sztywnego słownika słów, gdy w drugim tekście pojawia się słowo, które jest synonimem słowa z pierwszego tekstu, dodaje się je do wektora z wagą < 1.
Kluczowe elementy algorytmu:
Funkcja findSynonym(word) — szuka, czy dane słowo jest synonimem jakiegoś “głównego” słowa i zwraca [główne_słowo, waga].
termFreqMap(str, compareTo):
Domyślnie liczy zwykłe częstotliwości.
Gdy podamy compareTo (mapa z drugiego tekstu), to dla słów nieobecnych w compareTo sprawdza synonimy i dodaje je z odpowiednią wagą.
Reszta to standardowe cosine:
termFreqMapToVector → zamiana na wektory
vecDotProduct, vecMagnitude, cosineSimilarity
Jak to działa w praktyce? Przykład (na podstawie logiki):
Tekst A: “heavy rain” Tekst B: “big deluge”
Bez synonimów → podobieństwo niskie (brak wspólnych słów). Z synonimami → “big” ≈ “heavy” (waga np. 1.0), “deluge” ≈ “rain” (waga np. 0.8) → wysokie podobieństwo.
Algorytm jest asymetryczny w pewnym sensie (synonimy sprawdzane są w jedną stronę — z A względem B), co jest celowym projektem.
Cookie Consent
We use cookies to improve your experience on our site. By using our site, you consent to cookies.
Cookie Preferences
Manage your cookie preferences below:
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are needed for adding comments on this website.
Name
Description
Duration
comment_author
Used to track the user across multiple sessions.
Session
comment_author_email
Used to track the user across multiple sessions.
Session
comment_author_url
Used to track the user across multiple sessions.
Session
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Google Analytics is a powerful tool that tracks and analyzes website traffic for informed marketing decisions.
Contains information related to marketing campaigns of the user. These are shared with Google AdWords / Google Ads when the Google Ads and Google Analytics accounts are linked together.
90 days
__utma
ID used to identify users and sessions
2 years after last activity
__utmt
Used to monitor number of Google Analytics server requests
10 minutes
__utmb
Used to distinguish new sessions and visits. This cookie is set when the GA.js javascript library is loaded and there is no existing __utmb cookie. The cookie is updated every time data is sent to the Google Analytics server.
30 minutes after last activity
__utmc
Used only with old Urchin versions of Google Analytics and not with GA.js. Was used to distinguish between new sessions and visits at the end of a session.
End of session (browser)
__utmz
Contains information about the traffic source or campaign that directed user to the website. The cookie is set when the GA.js javascript is loaded and updated when data is sent to the Google Anaytics server
6 months after last activity
__utmv
Contains custom information set by the web developer via the _setCustomVar method in Google Analytics. This cookie is updated every time new data is sent to the Google Analytics server.
2 years after last activity
__utmx
Used to determine whether a user is included in an A / B or Multivariate test.
18 months
_ga
ID used to identify users
2 years
_gali
Used by Google Analytics to determine which links on a page are being clicked
30 seconds
_ga_
ID used to identify users
2 years
_gid
ID used to identify users for 24 hours after last activity
24 hours
_gat
Used to monitor number of Google Analytics server requests when using Google Tag Manager